CAP Theorem and Master–Slave Database Architecture
CAP Theorem
Section titled “CAP Theorem”The CAP Theorem (also known as Brewer’s Theorem) is one of the most important principles in Distributed Database Systems. It defines the trade-offs a distributed database must make between Consistency, Availability, and Partition Tolerance — the three essential properties of distributed systems. Understanding this theorem helps engineers design efficient, fault-tolerant, and scalable distributed databases based on the specific requirements of an application.
Breaking Down CAP
Section titled “Breaking Down CAP”Consistency (C)
Section titled “Consistency (C)”In a consistent distributed system, all nodes reflect the same data at any given time. When a write operation occurs, the update must be propagated to all replicas so that any subsequent read operation returns the most recent value.
Example: If a user updates their email ID in one node, any subsequent read from another node should immediately return the new email ID.
Key Point: All clients see the same data simultaneously, ensuring synchronized state across the cluster.
Availability (A)
Section titled “Availability (A)”A system is available if it remains operational and responsive even when some nodes fail. Every request — read or write — receives a response, though it may not always reflect the most recent data.
Example: Even if one server is down, other nodes continue serving requests without downtime.
Key Point: The system guarantees responsiveness but not necessarily the latest consistency.
Partition Tolerance (P)
Section titled “Partition Tolerance (P)”Partition tolerance refers to the system’s ability to continue functioning despite communication failures or network partitions between nodes. If a network partition occurs (e.g., some nodes can’t communicate), a partition-tolerant system remains operational by replicating and distributing data.
Example: If Node A cannot communicate with Node B due to network issues, both can still serve requests independently until communication is restored.
Key Point: A partition-tolerant system sacrifices either consistency or availability but not both.
The CAP Theorem Statement
Section titled “The CAP Theorem Statement”The CAP Theorem states that:
In a distributed system, it is impossible to guarantee Consistency, Availability, and Partition Tolerance simultaneously. A system can only provide two of these three properties at any given time.
Therefore, distributed databases must choose between consistency and availability when a partition occurs.

CAP in NoSQL Databases
Section titled “CAP in NoSQL Databases”NoSQL databases are designed to operate across distributed networks and are optimized for scalability and high availability. Depending on business needs, each NoSQL database prioritizes different combinations of CAP properties.
CA Databases (Consistency + Availability)
Section titled “CA Databases (Consistency + Availability)”- These databases maintain data consistency across all nodes and ensure high availability as long as no network partition occurs.
- They are not fault-tolerant because partitions (network failures) can cause system unavailability.
Example: Relational databases like MySQL or PostgreSQL configured with replication can function as CA systems in non-partitioned environments.
Use Case: Enterprise systems requiring consistent transactions but deployed in stable network environments.
CP Databases (Consistency + Partition Tolerance)
Section titled “CP Databases (Consistency + Partition Tolerance)”- These systems maintain data consistency and tolerance to network partitions, but sacrifice availability during a partition.
- If a partition occurs, inconsistent nodes are taken offline until synchronization is restored.
Example: MongoDB is a CP database. It uses a replica set with one primary node and multiple secondary nodes. Only the primary handles write requests; if it fails, a secondary becomes the new primary. During partitioning, unavailable nodes may reject requests to preserve consistency.
Use Case: Banking and financial applications where data accuracy is critical, and temporary unavailability is acceptable.
AP Databases (Availability + Partition Tolerance)
Section titled “AP Databases (Availability + Partition Tolerance)”- These databases guarantee availability and partition tolerance, but may return stale data during partitions.
- All nodes remain operational and eventually synchronize after partitions are resolved (eventual consistency).
Example: Apache Cassandra and Amazon DynamoDB are AP databases. They have no primary node, and all nodes can handle read/write operations. Data updates propagate asynchronously across the cluster.
Use Case: Social media platforms, messaging systems, and e-commerce websites where availability and speed matter more than strict consistency.
Summary Table – CAP in Databases
Section titled “Summary Table – CAP in Databases”| Database Type | Properties Ensured | Compromised Property | Example | Typical Use Case |
|---|---|---|---|---|
| CA | Consistency + Availability | Partition Tolerance | MySQL, PostgreSQL | Enterprise data centers with stable networks |
| CP | Consistency + Partition Tolerance | Availability | MongoDB | Banking, financial systems |
| AP | Availability + Partition Tolerance | Consistency | Cassandra, DynamoDB | Social media, real-time applications |
Design Implications of CAP
Section titled “Design Implications of CAP”When designing distributed systems:
- Choose CP for accuracy-sensitive systems (e.g., banking).
- Choose AP for availability-first systems (e.g., social media, streaming).
- CA systems work well only when network partitions are rare or negligible.
No single database satisfies all three properties simultaneously; instead, engineers must balance them based on application goals.
Master–Slave Database Architecture
Section titled “Master–Slave Database Architecture”Master–Slave Architecture is a database scaling pattern used to optimize I/O performance in systems with high read and write workloads. It follows the Command Query Responsibility Segregation (CQRS) principle — separating write and read operations to improve efficiency.
In this setup:
- The Master Database handles write (insert, update, delete) operations.
- The Slave Databases handle read (select) operations.
How It Works
Section titled “How It Works”-
Master Node:
- The primary source of truth.
- All updates (writes) are applied here.
- Data from the master is replicated to slave databases.
-
Slave Nodes:
- Read-only replicas of the master database.
- Serve user read requests to reduce load on the master.
- Updated through database replication mechanisms.
-
Replication:
- Can be synchronous (instant consistency) or asynchronous (eventual consistency).
- Ensures all slave nodes reflect master data periodically.
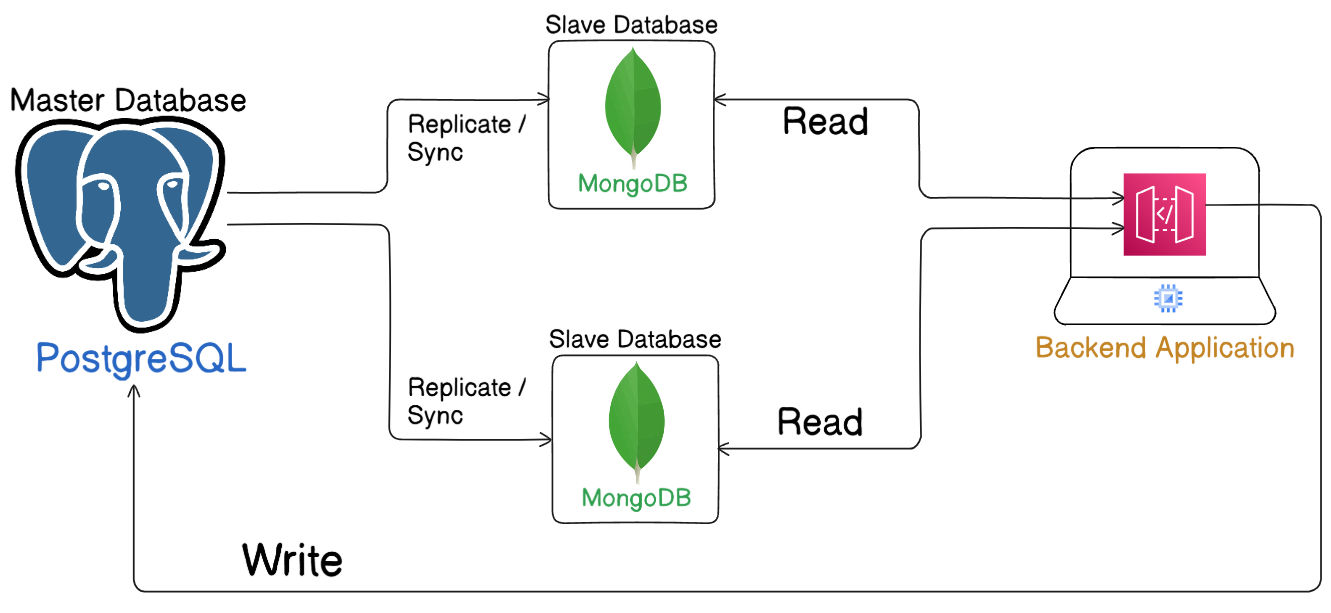
Example Workflow
Section titled “Example Workflow”- A user submits an update query → Directed to Master DB.
- Another user fetches data → Served from a Slave DB.
- Slaves synchronize with the master automatically to stay updated.
Advantages
Section titled “Advantages”| Benefit | Description |
|---|---|
| Load Balancing | Distributes read and write loads efficiently. |
| Improved Performance | Reduces read latency for high-traffic systems. |
| High Availability | System remains operational even if a slave fails. |
| Reliability | Master’s data is backed up across replicas. |
| Scalability | Additional slave nodes can be added easily. |
Example Implementation (MySQL)
Section titled “Example Implementation (MySQL)”-- On Master DBCREATE USER 'replica'@'%' IDENTIFIED BY 'replica_pass';GRANT REPLICATION SLAVE ON *.* TO 'replica'@'%';
-- On Slave DBCHANGE MASTER TOMASTER_HOST='master_host',MASTER_USER='replica',MASTER_PASSWORD='replica_pass',MASTER_LOG_FILE='mysql-bin.000001',MASTER_LOG_POS= 107;START SLAVE;This setup ensures all data written to the Master is replicated to Slave(s) in real-time or near real-time.
Use Cases
Section titled “Use Cases”- E-commerce platforms: High concurrent read/write activity.
- Analytics systems: Heavy read workloads on replicated slaves.
- Content delivery applications: Fast global read performance.
Key Points
Section titled “Key Points”- Master → Handles all writes (true source of data).
- Slave → Handles reads (replicated copies).
- Replication ensures data consistency across nodes.
- Ideal for systems emphasizing reliability, availability, and scalability under heavy traffic.
Conclusion
Section titled “Conclusion”Both the CAP Theorem and Master–Slave Architecture form the foundation of modern distributed databases:
- CAP Theorem defines the trade-offs among consistency, availability, and partition tolerance.
- Master–Slave Architecture practically implements scaling and reliability by distributing read and write operations.
Together, they help design robust, efficient, and high-performance distributed systems suited to real-world scalability demands.